We want to address this installation matter and ensure that it remains transparent, guaranteeing no unauthorized use of your resources (coin miner or whatever).
However, as a two-person team, with little to no help, balancing daily jobs and family responsibilities, we currently have limited capacity.
Regrettably, this means we cannot prioritize this issue at the moment.
So I am doing my first AI generated perfected by human script.
Here are my thoughts:
Am I a fan of this project? Yes definitely, I am officially a fan. Its great.
immediately rename Funscript AI Generator (FAG) to AI Funscript Generator (AFG) Before FAG sticks.
I it better than MTFG? Yes by far
Does it spare time scripting? Definitely. There are large parts that need no or almost no change. How much time is spared. Dunno how much yet. You still have to go through most points but minimal changes. This will get better as I see it.
How good are the scripts generated? I would say a lot better than from a beginner scripter or work from a scripter that gives a shit about endpoints. AFG does set endpoints well. Not yet perfectly not much advanced scripting yet. The script generated is usable which I can’t say some scripts that get published.
Can it handle all scenes? No, scenes you have difficulties yourself scripting won’t be much good in AFG either.
How good is detection of body parts? It’s amazing to live watch how good detection is.
Does it get better? As much as I see its still one an exponential scale. it will slow down soon when limits are hit.
How fast is conversion. With a string Nvidia conversion is really fast atm. Less than an hour for a 40 Minute 8K movie. Will slow down when more is processed but who cares if scripting takes 8 hours manually.
Installation is doable. Don’t forget to to change directory to the install directory in the Anaconda/Miniconda terminal screen.
GUI is easy to use.
They want to keep it public. Can not imagine it will be free forever but at least not shut away.
The Discord is super nice and super helpful. Oh look a scripter! They are really happy about people joining. Funny thing is they don’t seem to know this will skyrocket fast.
Scripts coming from AFG are free and can’t be sold which is great. So they are doing a big job for the community.
We’re back with an update packed with improvements, fixes, and exciting new features to make your experience smoother than ever!
What’s New? App Renamed to FunGen – A fresh identity to match its evolving capabilities! TensorRT Support – Faster inference, lower latency, and better performance on NVIDIA GPUs! Portrait Video Support – Full compatibility for vertical formats. Edit Video Settings Popup – Is our app not detecting the right format? Now this can be overwritten. Help Page Added – Get the guidance you need, right inside the app.
Bug Fixes & Optimizations Fixed generate debug video not adhering to start frame Fixed CLI argument handling for folders + improved logging Disabled YOLO analytics for better privacy Auto-load reference scripts for a smoother workflow Expanded debug overlays for deeper analysis General performance tweaks & minor bug fixes
New YOLO v12 Models! More accurate detection, improved recognition, and better tracking stability, especially in tricky scenes!
Sneak Peek: Tracking 2.0 for Enhanced Funscript Generation!
We’re making big improvements to our funscript generation!
It’s a work in progress (and not released), but early results look fantastic—expect better scripts, better handling of tricky positions, and overall higher quality.
Stay tuned for more updates!
Give it a spin and let us know your feedback!
Note: make sure to re-install the requirements if updating:
pip install -r core.requirements.txt
and if on NVIDIA:
pip install -r cuda.requirements.txt
pip install tensorrt
Would be cool to just show the boxes without the movie and see if the viewer can imagine a funscript from those boxes as that is what Fungen sees only.
I can get this running, but I can’t figure out the .bat file for batch production.
If I try to do anything else on my system, it freezes and crashes – so this is really resource intensive and maybe could have some more efficient error-checking in the code. Which I’m sure isn’t easy – so, what might be easy is a pause button for processing. Right now it’s all or nothing it seems – “Stop processing” after 40 minutes makes it look like I will lose my progress. But I’d like to have this run while I’m not on the computer, so I’d pause it when I’m here.
If I hit “stop processing”, and start again, will it pick up where I left off?
Well, we would need a bit more info on your hardware setup, the model version and code version you are using, etc. before knowing where the issue might be located.
Happy to discuss this in the Discord.
Anyway, at the moment, you cannot pause the processing of a single video and resume it afterwards.
However, if you stop a batch processing, re-running it will have the program skip all the videos for which a funscript was generated.
And we have less time to work on this type of feature for now, as we are trying to focus on the new major version.
A very quick update for you folks, while spatialflux is away for a couple days of very well deserved rest.
I decided to dive in again in the Prod version as the new version is gonna to take a damn effin while to release.
Wanted to try and see if I could improve some stuff in there before we end up giving birth to this huge baby coming ahead.
First, performance wise , the new version under development is going to be a killer, specifically on the YOLO inference side. I have no gains on that part to offer on the prod version, but the second stage of generation now is down from 8 / 10 mins to barely 15 seconds.
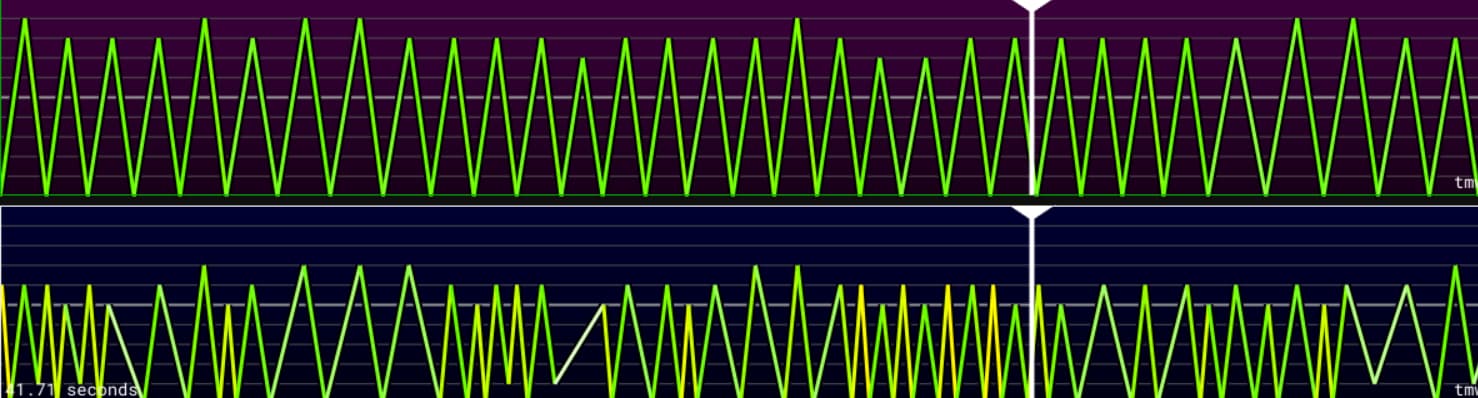
Second, in term of quality of signal . This quick screenshot to show that we now ditch some of the annoying unwanted moves (hands or feet passing over, etc.). Here an example, blue line being the base prod version, green one being the tweaks of the prod version I am referring to. Still need quite some work, but looking good !
It even looks like we might’ve here a fix for the issue @roa mentioned of being a couple frames late in terms of endpoint (prod funscript in blue, tweaked version signal in green)
Regarding the YOLO model, you need to use the menu View → Settings and select the right model file from there. Ideally, restart the app after selecting the model.
I’ve tried it now for some days and even compared it to some scripts I’ve commissioned from talented manual scripters. It’s better than the OFS plugins for mocap. Mainly because it does detect objects better and doesn’t stop 50 times per video like the OFS plugin.
It is however, far from being something you can just use and generate a ready-to-use end result. It can do SOME parts well enough that the end points are at least fairly accurate. But most of the time it will create nonsense. Funnily enough, the first video I tried it with was actually fairly usable. But every video after that has been just nonsense.
I was hoping that it would be able to have end points largely on point so I could just manually fine tune things and not have to spend an hour per 5 minutes of video doing scripting. But it produces so much nonsense that it does not save time in most cases. It will add extra end points for no reason or just stop generating end points even when there’s clearly movement. So you can’t just navigate from end point to end point doing fixes. You will actually have to scrub the parts in between points to see what it has missed or done wrong. Sometimes even suddenly reversing the motion. Just like you would have to with other generator-type plugins or tools.
Here are some comparison images from OFS. Top one is manually scripted, bottom is generated.
Here are some snippets where it really struggled against a human:
AI will of course only get better and better over time and the developers are working hard to improve things. The community there in their Discord is very helpful if you want to get started. But as of now I would wait and see how things develop. It’s at a very early stage and I am confident that it will get better and better. Since the generation process is fast, especially if you have good hardware, seeing as it does perform fairly well with some scenes, it has some uses even at this point. But I have not been able to generate a full video that would not have required me to spend almost as much time as I would have had to if I was manually scripting.
As discussed in the Discord, the difficult parts spotted here mainly happen during HJ/BJ scenes, during body parts hovering on the penis area, when movement is not seen (hidden) or when body parts are not detected (extremely low in the frame for instance).
These are being worked on, and we have some workarounds implemented.
2 versions are/were in the work, one full rehaul (tough in the making, will take much much longer) along with spatialflux and one being a rework of some components leading to better results.
Both of these versions are more context-aware, identifying what is the most likely position, discarding unrelevant body parts or just hovering body parts from the computation.
And now we can apply a proper boost based on context, when we have very low signal, in some HJ/BJ scenes for instance, enhancing and capping to 100-50 or whatever.
The signal is now more solid. And identifying peaks and valleys in a different approach, trying to get better at grabbing the endpoints than what we had with the Visvallingham Whyatt algorithm combined by the moving average.
While you’re right about the extreme low in the video and the obvious difficult sections such as obsctructed view and BJ/HJ, which are challenging to human scripters as well, it also struggles greatly with missionary and cowgirl scenes where the action is definitely not extremely low on the video. Unless 20-25% is considered very low. Then all missionary and cowgirl scenes are a no go.
My main point is that I gave my opinion of the current state of it. Especially since I felt that some earlier reviews were (characteristically) overly optimistic. As it often is with where people see potential in a new technology. People tend to put on rose-tinted glasses.
I don’t know if anyone still remembers how bad the first versions of the AI image generators were when they become more public knowledge. Novel but utterly unusable. A year from that point they were already exponentially better. Look at where they are nowadays, only few years afterwards. I have no doubt the tool will get better and better and the progress will be surprisingly fast.