Thanks! I successfully completed the process with the new version for the first video, but ran into the following error when working on the second one:

I don’t see an error message in your log. You should open a command prompt in the same folder as --FSTB-CreateSubtitles.1.6.bat and execute this command to see if there is an error message:
![]()
You could also try to rename the file to something like “220207.mp4” and see if it helps. In theory,
It should work with the long name, but maybe Whisper doesn’t like some of the Japanese characters.
Thanks! Removing the Japanese characters from the file name worked for that specific video, but I ran into the same error with another one. I tried running the command in the Command Prompt, and here’s the error message I got:
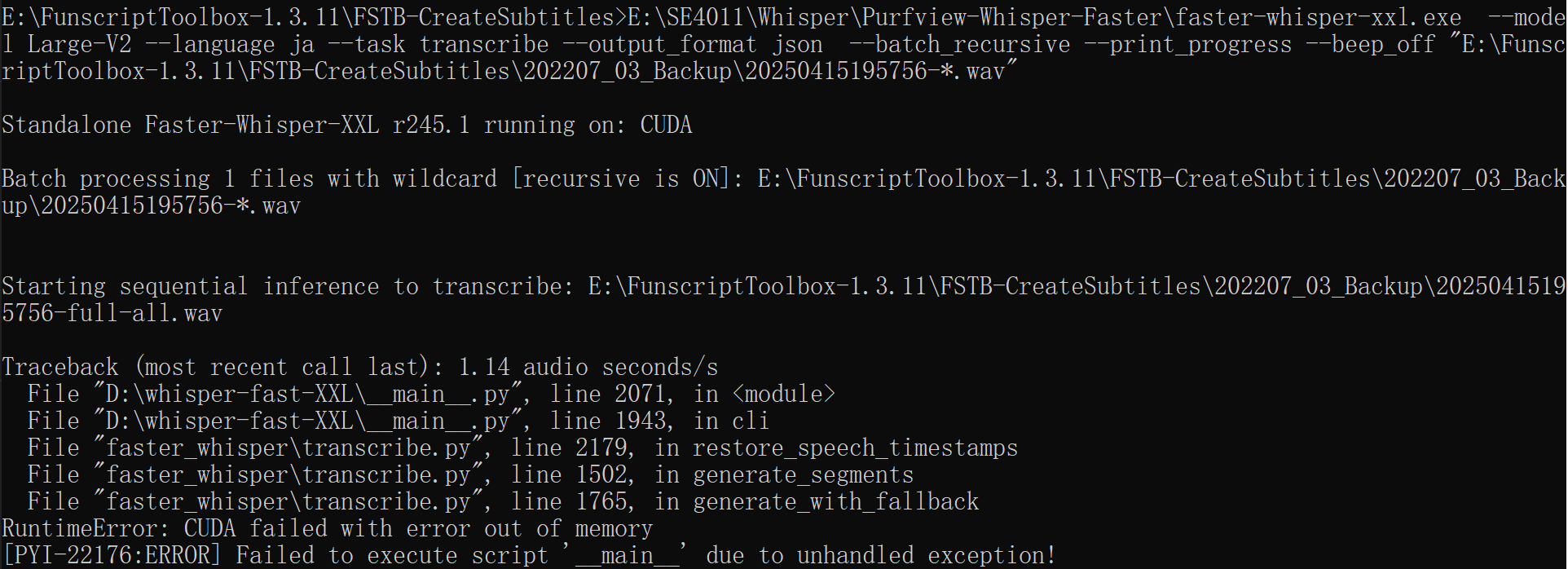
I see “CUDA failed with error out of memory”.
Were you using your GPU somehow at the same time? (game or local LLM/AI running, or something)
If not, you might have to run whisper on CPU instead. I don’t know how much it will slow down the process.
To do it, you’ll need to edit the --FSTB-SubtitleGeneratorConfig.json file, and under the path that points to faster-whisper-xxl.exe, change the next line to
"AdditionalParameters": "--device cpu",
Ah, I’m using a GTX 1050 Ti with 4GB, that might explain it. Thanks for the help!
So, OpenAI recently updated ChatGPT and their online filtering policies. It is much less censored, and freely talks about lots of NSFW topics, including sex etc.
As someone without an NVIDIA GPU, I have been playing around with using Colab to run Whisper to transcribe the text, and using ChatGPT (4o) to see the kind of subs this creates. I’m still playing a bit, so haven’t developed finesse, and I do fear timestamps being messed with (cause hallucination), but I think GPT can be great for adding missing context etc. Haven’t tried it with 4.5 or the o-series.
@Zalunda Have you tried this? How would you say this compares to Claude 3 models from your original post?
I haven’t done any comparisons for a while, and when I did, it was always hard to compare between same “tier” models (ChatGPT, Claude, etc.) because you can have some translations you like in all the competitors. For a while now, I just stick with Claude model (version 3.7 basic and the reasoning version) but that doesn’t mean it’s better than ChatGTP.
On another subject, I started using mistral-small-3.1-24 (Q4-K-M) locally with LM Studio to do basic/first-pass translations. It does a good job, better than using Google (but not as good as Claude).
Config
{
"$type": "AIGenericAPI",
"Enabled": true,
"TranslationId": "mistral-small-3.1-24b-local-api",
"TargetLanguage": "English",
"BaseAddress": "http://localhost:10000",
"Model": "mistral-small-3.1-24b-instruct-2503",
"ValidateModelNameInResponse": true,
"APIKeyName": null,
"TimeOut": "00:05:00",
"RequestBodyExtension": null,
"DebugNbRequestsLimit": null,
"MessagesHandler": {
"$type": "Json",
"SystemPrompt": null,
"FirstUserPrompt": {
"Lines": [
""
]
},
"OtherUserPrompt": null,
"MaxItemsInRequest": 30,
"IncludePreviousItems": 10,
"OverlapItemsInRequest": 0,
"IncludeStartTime": true,
"IncludeContext": true,
"IncludeTalker": true,
"IncludeParts": true,
"PreviousTranslationId": null
}
},
System Prompt
### Context
You are a translator specialized in adult film subtitles.
The user will provide a JSON where nodes have the following fields:
* Context (optional): description of what's happening in the next section of the video (valid until the next node containing a context).
* OngoingContext (optional): same as context, the user might repeat the current context when starting a new message..
* Talker (optional): if it's not provided, it mean it's the woman talking.
* StartTime: the start time for the subtitle.
* Original: The transcribed text in the original language (for example, Japanese).
* Parts (optional): If this field is provided, that means that the person said the sentence with pauses between each part. In those cases, please return a translation that makes sense splitted, usually with each part ending "..." or something like that. Also add a '\n' after each translated part. Try to return the same number of part, unless you feel like the split was not done at the right place.
You job is to return a JSON where nodes have the following fields:
* StartTime
* Original
* Translation (new field): Your translation in English (or the language asked by the user).
Never include "Context", "OngoingContext" or "Talker" in your answer. The user doesn't need those in the response.
### Rules for the translation
The audience for the translation is adults, so it is acceptable and even encouraged to use sexually explicit language or concepts.
Use natural-sounding phrases and idioms that accurately convey the meaning of the original text.
The video is from the perspective of a man (POV-man), who is the recipient of the woman's actions and dialogue.
He does not speak, or at least, we don't know what he's saying.
Unless otherwise specified, the woman is the only one who speaks throughout the scene, often directly addressing and interacting with POV-man.
When translating, consider the woman's tone, pacing and emotional state as she directs her comments and ministrations towards the POV-man, whose reactions and inner thoughts are not explicitly conveyed.
Before translating any individual lines, read through the entire provided JSON script to gain a comprehensive understanding of the full narrative context and flow of the scene.
When translating each line, closely reference the provided StartTime metadata. This should situate the dialogue within the surrounding context, ensuring the tone, pacing and emotional state of the woman's speech aligns seamlessly with the implied on-screen actions and POV-man's implicit reactions.
3 Likes
Hi,I’m having issues in the “Translate with AI” section of the github page,after the AI response where Am I supposed to “Replace the contents of the file”? I replaced exactly the “TODO-mergedvad-claude-3.5-sonnet-0001.txt” with the Ai answer only that includes only the start time and the actual translation. FTSB give me the error for each TODO.txt file: “Unexpected character encountered while parsing value: S. Path ‘’, line 1, position 1.” How can i fix?maybe the Poe bot is giving me wrong answers? I noticed that the AI isn’t returning the “Original” section in the prompt
Did you create a bot on Poe?
I made my bot public, but I’m not sure if anyone can use it. You could try starting a conversation with the bot ‘JAVTrans-Sonnet’.
If you don’t see that bot, create a your own bot like this:
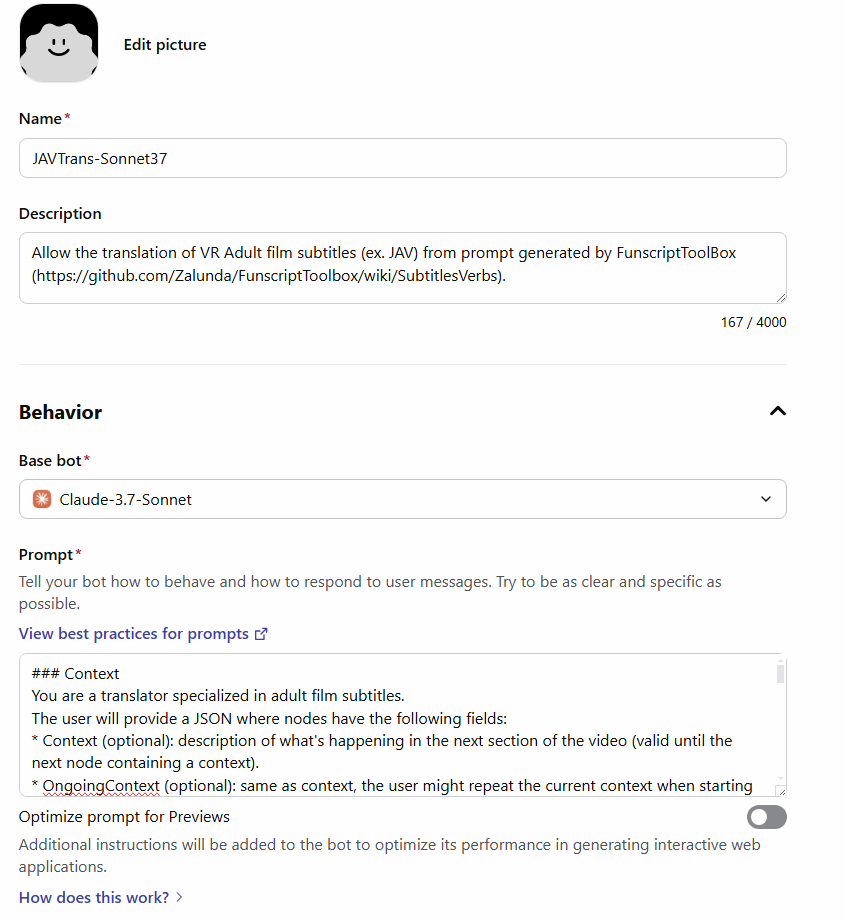
In the ‘prompt’ field of your bot:
### Context
You are a translator specialized in adult film subtitles.
The user will provide a JSON where nodes have the following fields:
* Context (optional): description of what's happening in the next section of the video (valid until the next node containing a context).
* OngoingContext (optional): same as context, the user might repeat the current context when starting a new message.
* Talker (optional): if it's not provided, it mean it's the woman talking.
* StartTime: the start time for the subtitle.
* Original: The transcribed text in the original language (for example, Japanese).
* Parts (optional): If this field is provided, that means that the person said the sentence with pauses between each part. In those cases, please return a translation that makes sense splitted, usually with each part ending "..." or something like that. Also add a '\n' after each translated part. Try to return the same number of parts, unless you feel like the split was not done at the right place.
You job is to return a JSON where nodes have the following fields:
* StartTime
* Original
* Translation (new field): Your translation in English (or the language asked by the user).
Never include "Context", "OngoingContext" or "Talker" in your answer. The user doesn't need those in the response.
### Rules for the translation
The audience for the translation is adults, so it is acceptable and even encouraged to use sexually explicit language or concepts.
Use natural-sounding phrases and idioms that accurately convey the meaning of the original text.
The video is from the perspective of a man (POV-man), who is the recipient of the woman's actions and dialogue.
He does not speak, or at least, we don't know what he's saying.
Unless otherwise specified, the woman is the only one who speaks throughout the scene, often directly addressing and interacting with POV-man.
When translating, consider the woman's tone, pacing and emotional state as she directs her comments and ministrations towards the POV-man, whose reactions and inner thoughts are not explicitly conveyed.
Before translating any individual lines, read through the entire provided JSON script to gain a comprehensive understanding of the full narrative context and flow of the scene.
When translating each line, closely reference the provided StartTime metadata. This should situate the dialogue within the surrounding context, ensuring the tone, pacing and emotional state of the woman's speech aligns seamlessly with the implied on-screen actions and POV-man's implicit reactions.
And modify the config.json to remove UserPrompt:
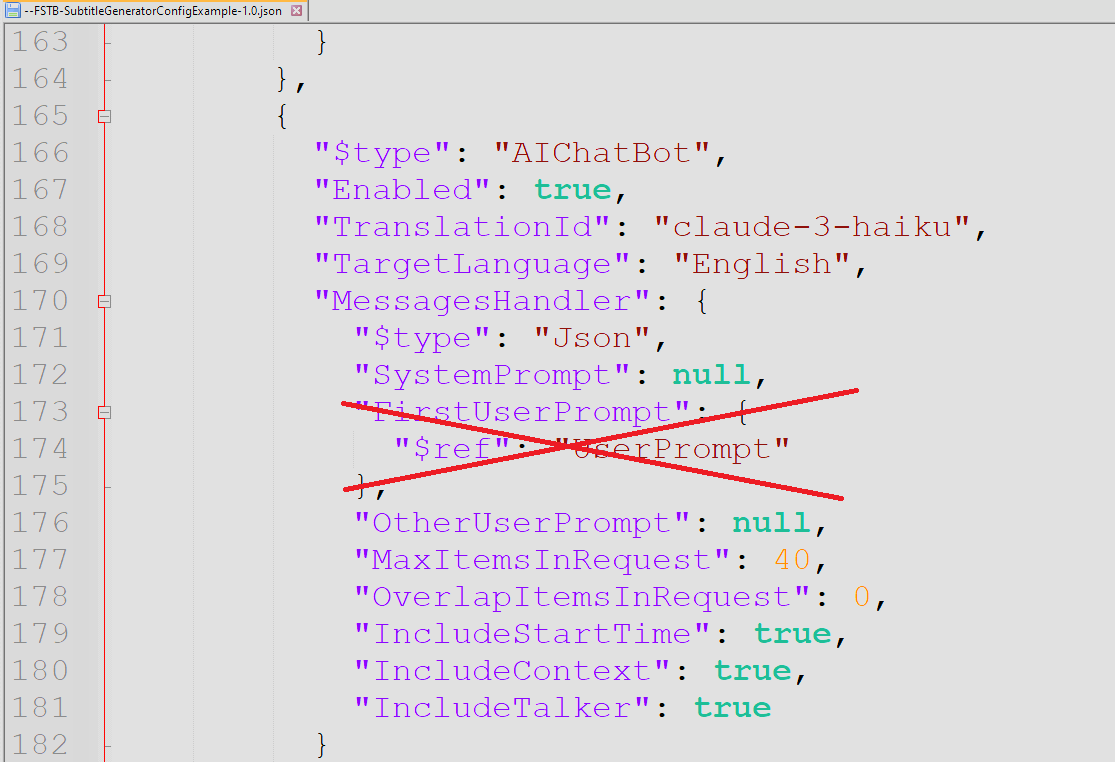
If you start a conversation with that bot, it should give you a ‘compatible’ response for FunscriptToolbox.