TLDR;
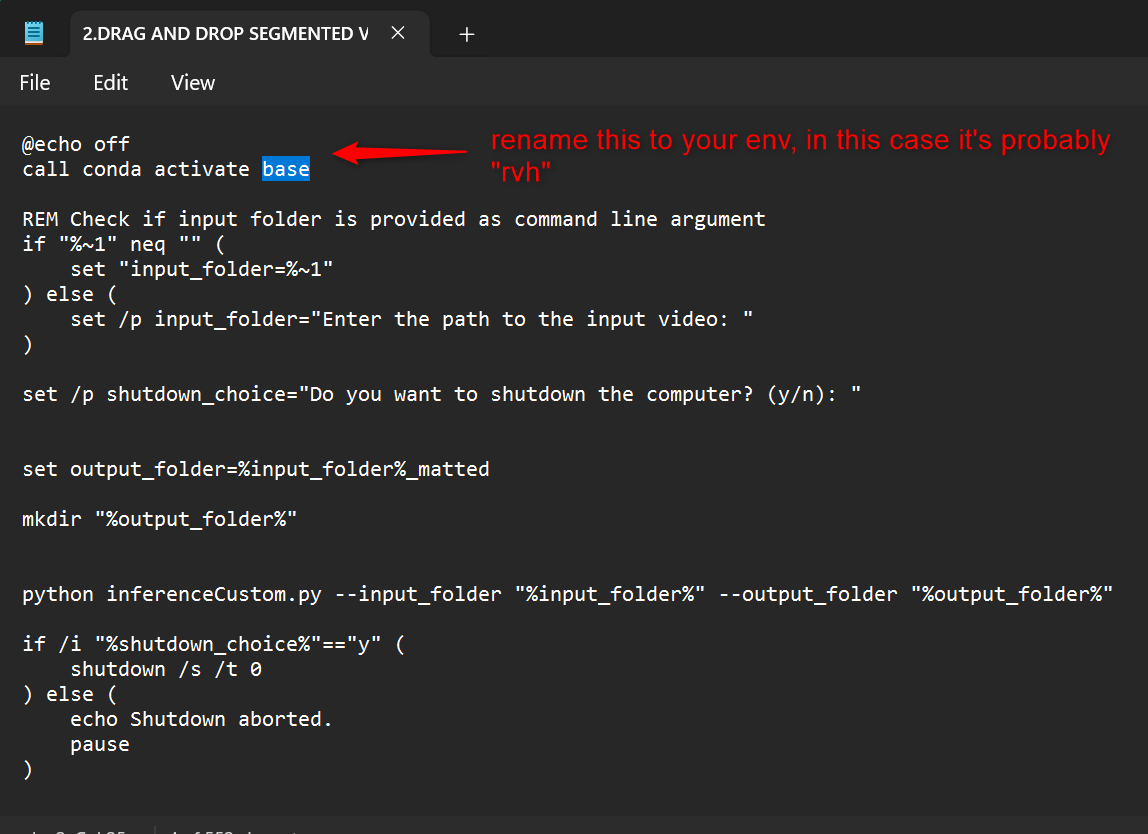
Extract this github repo and read the readme to make your own passthrough videos!
Hello! ![]()
As some of you may know I’ve been investigating the best way to create passthrough videos on my own because there’s so little Passthrough content out there ![]()
Problem
For some videos they tend to either be AI-generated Passthrough done through some form of Semantic Matting/SegmentAnything that looks blobby and keeps the male actor body, which can be a bit immersion breaking:

Or it’s already greenscreened from the start;
but for some reason the way the alpha matte is packed into the videos (Those red masks) appears to be anti-aliased to the point that you could literally see the pixels + sometimes looking blobby too due to some kinda matte erosion:

So i set off on a journey to find the best way to make passthrough videos to enable my escapist fantasies ![]()
Research and Development
I tried a whole bunch of methods to try to get a good result:
- SegmentAnything
- Mask2Former
- SemanticGuidedHumanMatting
- Media Pipe Selfie Matting
- High-Quality Segmentation Refinement
Most of these encountered problems trying to identify “what is a human” in VR distorted frames, i believe it’s because these models were not necessarily trained on distorted VR images of humans so it can’t do a good enough job!
And then i found this! ![]()
BackgroundMattingV2:
A simplified explanation is that:
Using the power of neural networks, it’s able to intelligently compare a still “cleanplate” without anyone in it, and use that to create mattes on objects that are moving on top of that “cleanplate”
(which means it does not need to know what a human is and try to matte those out, like typical semantic matting )
Pros:
- Retains alot of fine hair details!
- Quite fast to process each image!

Cons:
-
You need to build your own cleanplate from all the different frames of the video using photoshop to get any satisfactory results!
-
You need a lot of disk space, and you need to pre-render the frames into images.
-
Lots of setup work required + clean-up work after to get something decent especially if the male actor moves around too much.
-
Only really works for scenes where i was able to build cleanplates out of, so no scene or position changes.
Then i found that the authors of this paper published an even better version of this but addressed the cleanplate problem!
RobustVideoMatting:
It basically works the same but it uses the last 4 frames as “memory” to build up the cleanplate.
Pros:
- Robust, works with lots of different positions and scene changes!
- Does not require manual work to make it work and the matting quality scales by footage quality! (if you can get extremely high-quality footage such as those from JAV studios, it makes it literally mindblowing how much hair detail gets retained )
- The male actors tend to get keyed out because they are mostly stationary so that’s great!


Cons:
- Really fumbles on long form videos, will crash and burn and you lose hours upon hours of processing!
- On long form videos the matting seems to “lose the plot” per-se, i believe this might be due to memory problems.
- You can’t stop it once it gets going so you basically will need a dedicated machine running to keep it going.
The Pipeline:
So to address these problems, I basically created a pipeline assisted by Batch files and a python script.
The pipeline works by:
- Cutting up the original video into segments of a few seconds each ( how many seconds is up-to-you really! )
- Inferring on each of those video segments
2.1. If a segment fails or the process is stopped, it will be recorded in a .json file and can be restarted later. - After Inference, we combine the matted segments back together into one video
- Copy audio from original video to combined matted video
It improves on the original RVM Codebase because:
- You can stop the process at any time and just restart it and it will restart from the last file it didn’t process.
- If a decoding error happens, it will only kill that segment and move on with the rest so you can fix that after and restart the process
- Makes it a lot more viable to process 8K videos on lower-end systems without as much VRAM ( theoretically it should work since we’re only loading in a few seconds 8K video each time )
- Makes it viable to distribute processing across different machines so it’s literally perfect for bigger studios with the resources to do it
Feel free to modify the code and submit pull requests if you’re technically-inclined and want to help out ![]()
I hope this will allow a lot of people to create more passthrough videos or maybe even bigger studios to start adopting this so we can have better passthrough videos!
Also I see it a a way to give back to this community ![]()
Also here’s a catalogue of my funscripts if you’re interested in funding my escapism