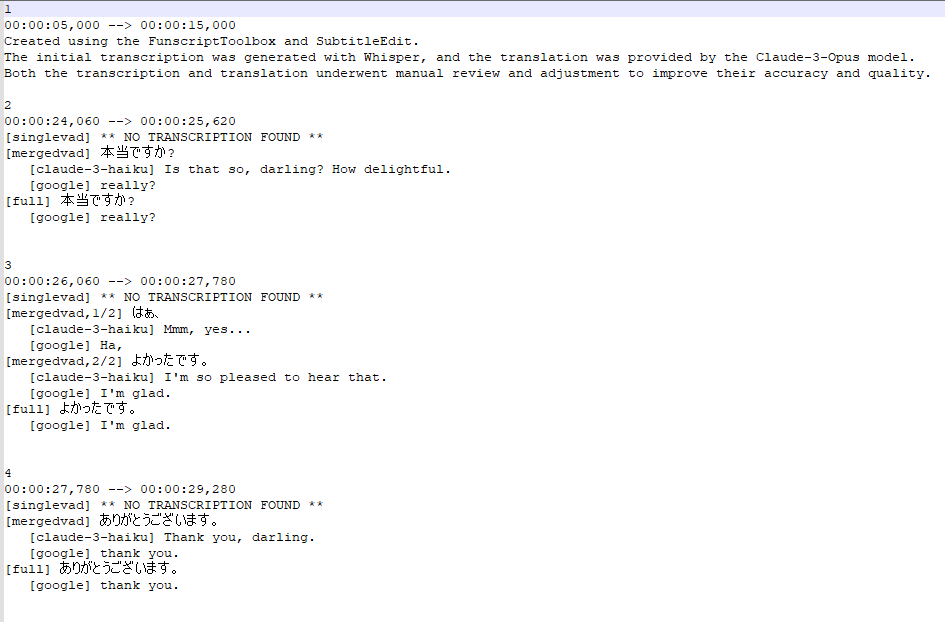
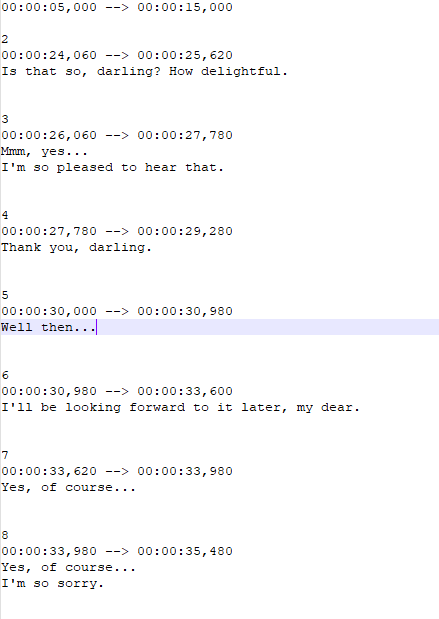
This is controlled by the WIPSrt output in the Config.json file:
...
{
"$type": "WIPSrt",
"Description": "WIPSrt: .wip.srt",
"Enabled": true,
"FileSuffix": ".wip.srt",
"TranscriptionsOrder": [
"singlevad",
"mergedvad",
"*"
],
"TranslationsOrder": [
"claude-3-opus",
"claude-3-sonnet",
"claude-3-haiku-200k",
"claude-3-haiku",
"chatgpt-4",
"mistral-large",
"local-mistral-7b",
"deepl",
"deepl-files",
"google",
"*"
],
...
You could simplify it by removing all the transcriptionId & translationId (and the last “*”) that you don’t want to see (and then, rerun the application):
{
"$type": "WIPSrt",
"Description": "WIPSrt: .wip.srt",
"Enabled": true,
"FileSuffix": ".wip.srt",
"TranscriptionsOrder": [
"mergedvad"
],
"TranslationsOrder": [
"claude-3-haiku"
],
In that case, you would get only:
[mergedvad] 気持ちいい [2/3, 85%]
[claude-3-haiku] Feels good.
Right now, it’s not possible to reduce it even more (when using ‘perfect-vad/mergedvad/WIPSrt’ process, which gives the best result IMO).
At some point, I could add an option to detect if there is a single ‘choice’ for a subtitle and use it as-is (i.e. Feels good) and concatenate strings (i.e. Oh, I really like you.) if it has something like this (i.e. multiple transcriptions for a single ‘perfect-vad’ timing).:
[mergedvad,1/2] 気持ちいい
[claude-3-haiku] Oh,
[mergedvad,2/2] 気持ちいい
[claude-3-haiku] I really like you.
But I wouldn’t be able to simplify when a transcription overlaps multiple timings, or you would end up with 3 subtitles with the same text:
(subtitle #1)
[mergedvad] 気持ちいい [1/3, 30%]
[claude-3-haiku] This is a really long sentence, that overlap multiple timing and that should be split the user.
(subtitle #2)
[mergedvad] 気持ちいい [2/3, 36%]
[claude-3-haiku] This is a really long sentence, that overlap multiple timing and that should be split the user.
(subtitle #3)
[mergedvad] 気持ちいい [3/3, 44%]
[claude-3-haiku] This is a really long sentence, that overlap multiple timing and that should be split the user.